
Wir betreiben einen Zeitschriftenclub, in dem jeden Freitag um 14.00 Uhr datenwissenschaftliche Themen diskutiert werden. Um unserer Mailingliste beizutreten und Benachrichtigungen zu erhalten, senden Sie bitte eine leere E-Mail an odsl-subscribe(at)lists.lrz.de oder besuchen Sie diese Website: https://lists.lrz.de/mailman/listinfo/odsl.
Wenn Sie Ideen für zu diskutierende Themen haben, können Sie diese gerne in der folgenden Google-Doku vorschlagen: http://bit.ly/odsljc20.
Diese Informationen sind nur auf der englischen Website verfügbar.
Dieser Abschnitt ist nur in englischer Sprache verfügbar.
An introductory C++ course will take place 8.3.-19.3.2021. Exam 19.3.
Moodle page: https://www.moodle.tum.de/course/view.php?id=64027
Students may also register as guest (please get into contact with alice.smith-gicklhorn@origins-cluster.de to get access)
On the Moodle-page, information on the course, slides and literature for download may be found.
The course takes place online via zoom::
https://cern.zoom.us/j/63382034823?pwd=VHF3T1VCOWpybjN4MmRFWUcySU5SQT09
Meeting ID: 633 8203 4823
Passcode: (please get into contact with alice.smith-gicklhorn@origins-cluster.de to get the passcode)
Dates:
8.3.2021-19.3.2021. (examen: 19.3.2021 - ECTS credits 3)
Times:
10.00 to 12 - 12.30 (2 lectures 20-20 slides each)
14.00 to 16 - 17 practical part (students are programming, lecturer answers their questions)
Lecturer: Sergei Gerassimov
Language: English
Wir organisiert im Zeitraum 1.-11 März 2021 zwei Blockkurse zur Einführung in Statistische und Monte Carlo Methoden.
Die Kurse, wie auch die Tutorien, werden online stattfinden.
Die Blockkurse folgen dem Zeitplan:
Vorlesung: Montag-Mittwoch 14:00-17:00
Tutorium: Dienstag-Donnerstag 9:00-12:00
Alle Übungen werden vor den Kursen zur Verfügung gestellt und der Abgabetermin für den Bericht ist der 31. März.
Für die erfolgreiche Teilnahme an beiden Blockkursen werden ECTS-Punkte vergeben.
Dozent: Prof. Allen Caldwell
Themen: Ableitung und Anwendung der gebräuchlichsten statistischen Verteilungen, Zentraler Grenzwertsatz, Punktschätzungen, Konfidenzintervalle, Teststatistik, p-Werte und verwandte Themen.
Dozent: Prof. Allen Caldwell
Themen: Variablentransformationen, Annahme-Ablehnungs-Methoden, Stichprobenmittelwert, Wichtigkeitssampling, Random Walks, Markov Chain Monte Carlos und Anwendungen
Die Anmeldung zu den Kursen, sowie weitere Informationen finden sich unter: https://indico.ph.tum.de/event/6797/
Dieser Abschnitt ist nur in englischer Sprache verfügbar.
Das Origins Data Science Labor (ODSL) organisiert zwei Blockkurse von je drei Nachmittagen zu datenwissenschaftlichen Themen.
Jeder Block besteht aus sechs einstündigen Vorlesungen, gefolgt von der Möglichkeit, an einer Reihe von Problemen zu arbeiten, einschließlich kleiner Berechnungen und Implementierungen.
In diesem Kurs werden wir die grundlegenden Konzepte des Denkens der Unsicherheit einführen. Nach einer kurzen Einführung in die Wahrscheinlichkeitstheorie und häufig verwendete Wahrscheinlichkeitsverteilungen diskutieren wir Inferenzaufgaben mit verschiedenen probabilistischen Modellen. Abschließend skizzieren wir Methoden zur Annäherung an komplexere Inferenzaufgaben durch Approximation oder Stichprobenziehung.
Dozent: Jakob Knollmüller
Voraussetzungen: Lineare Algebra, Grundlagen Analysis, eine Programmiersprache nach Wahl
Erworbene Fertigkeiten: Grundlagen des probabilistischen Denkens und der Bayes'schen Inferenz, probabilistische Modellierung, Modellvergleich, approximative Inferenz
Dieser Kurs konzentriert sich auf Methoden zur Datenverarbeitung, Optimierung und maschinelles Lernen. Zuerst lernen wir die Grundlagen der Datendekorrelations-, Reduktions- und Optimierungsalgorithmen kennen. Basierend auf diesen neuen Fähigkeiten tauchen wir in Themen des maschinellen Lernens ein, wie z.B. Clustering, Klassifikation und Regression mit baumbasierten Algorithmen und neuronalen Netzen. Im letzten Teil werden Modelle des maschinellen Lernens und verschiedene Architekturen vorgestellt und erklärt.
Dozent: Dr. Philipp Eller
Voraussetzungen: Lineare Algebra, Grundlagen Analysis, eine Programmiersprache nach Wahl
Erworbene Fähigkeiten: grundlegende Datentransformationen, Kenntnisse in verschiedenen Optimierungsalgorithmen, k-means-clustering, decision trees, neural networks, convolutional neural networks, auto-encoders, generative models
Es ist möglich, eine Zertifizierung oder ECTS-Punkte für die Teilnahme an den Blockkursen zu erhalten:
Um ein Teilnahmezertifikat zu erhalten (entweder für einen der beiden Blöcke oder für beide), müssen Sie Lösungen zu den Übungen einreichen, die während des Kurses aufgegeben werden, und eine genügende Note errecihen. Das Zertifikat wird kursweise ausgestellt und besagt, dass Sie den Blockkurs in dem jeweiligen Thema erfolgreich abgeschlossen haben. Bitte melden Sie sich für den Kurs im Voraus an, damit wir abschätzen können, wie viel Arbeit die Auswertung der Berichte in Anspruch nehmen wird.
Um die 3 ECTS-Punkte zu erhalten, müssen Sie Lösungen zu den Übungen für beide Blockkurse einreichen, die in diesem Jahr angeboten werden. Die Note für den Kurs wird auf den beiden Übungssätzen basieren, und es wird keine zusätzliche Prüfung geben. Die Abgabefrist für den Bericht ist der 30. September 2020. Bitte melden Sie sich für die Kurse im Voraus an, damit wir abschätzen können, wie viel Arbeit die Auswertung der Berichte in Anspruch nehmen wird.
Für weitere Informationen und zur Anmeldung besuchen Sie bitte https://indico.ph.tum.de/event/4491/
Der Workshop wird sowohl einführende als auch fortgeschrittene Themen im Bereich der statistischen Stichprobenziehung (Sampling )und Clusterbildung behandeln. Neben Vorträgen über den neuesten Stand der Technik wird der Workshop auch Hands-on und Übungssitzungen umfassen.
Der vom Max-Planck-Institut für Physik (MPP) veranstaltete Workshop wird von INSIGHTS ITN, MPP IMPRS und dem Exzellenzcluster ORIGINS organisiert und steht allen Angehörigen dieser Organisationen offen.
Aufgrund von Covid-19 werden alle Vorlesungen, Übungseinheiten und sozialen Interaktionen online abgehalten.
Abhängig von der weiteren Entwicklung der aktuellen Situation kann es immer noch möglich sein, zum MPP zu reisen, um persönliche Kontakte zu knüpfen.
Die Teilnahme ist kostenlos, aber alle Teilnehmer sollten sich bis zum 20. September 2020 anmelden.
Mehr infos: https://indico.mpp.mpg.de/event/7494/overview

Um ein gutes Bild einer räumlich variierenden Größe, einem Feld, aus unvollständigen und verrauschten Messdaten zu rekonstruieren, bedarf es der Kombination der Messungen mit Wissen über allgemeine physikalische Eigenschaften des Feldes, wie dessen Glattheit, Korrelationsstruktur, oder Divergenz-Freiheit. Die Informationsfeldtheorie nutzt den eleganten Formalismus von Feldtheorien, um optimale bayesianische Bildgebungsalgorithmen für die unterschiedlichsten Messsituationen mathematisch herzuleiten. Diese Algorithmen können mittels des „Numerical Information Field Theory“ (NIFTy) Programierpaketes effizient und allgemein implementiert werden. Algorithmen die NIFTy nutzen kommen beispielsweise bereits in der Radio- und Gammastrahlungsastronomie zum Einsatz. NIFTy entwickelt sich gerade zu einem universell einsetzbaren Werkzeug für Bildgebungsprobleme in Astronomie, Teilchenphysik, Medizin und andere Gebiete.
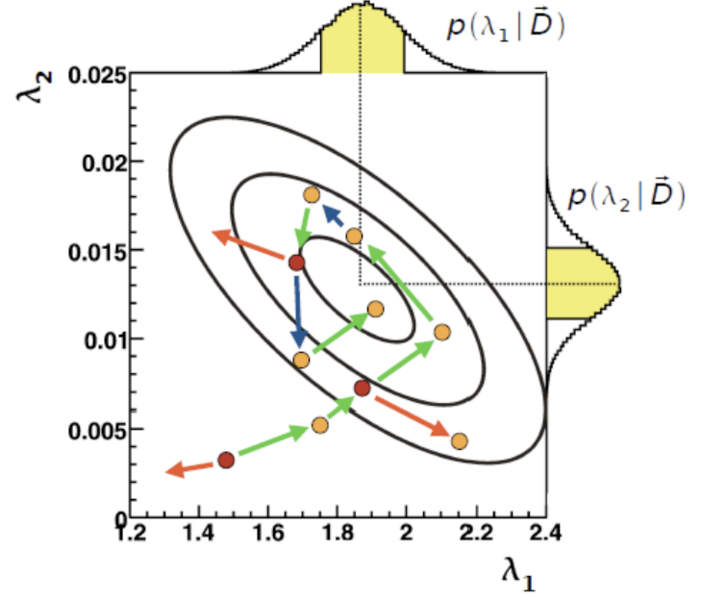
Das ”Bayesian Analysis Toolkit” (BAT) ist ein Softwarepaket, welches die Lösung statistischer Probleme mittels der Bayesschen Statistik ermöglicht. BAT basiert auf dem Bayesschen Theorem und nutzt sogenannte Markov Chain Monte Carlo Methoden. Dies ermöglicht den Zugang zur vollen A-posteriori-Wahrscheinlichkeitsverteilung und damit eine einfache Parameterbestimmung, sowie Begrenzung und Fortpflanzung von Unsicherheiten. Mittels neuer Stichprobenverfahren, Optimierungsschemata und Parallelisierungsmethoden kann dieses vielseitige Werkzeug in den kommenden Jahren erweitert werden.
ORIGINS wird eine Datenbank aufbauen um alle vorhandenen Informationen zum Thema "Dunkle Materie" zu sammeln. Es werden Daten aus experimentellen Studien, astronomischen Beobachtungen und von theoretischen Modellen kombiniert um einen einfachen Vergleich von Theorie und Beobachtung zu ermöglichen. Dies trifft speziell auf die Suche nach möglichen Kandidaten für „Dunkle Materie“-Teilchen zu, welche dann – auf einfache Weise – mit vorhandenen Experimenten und Theorien aus der Kosmologie, der Astro- und Teilchenphysik bestätigt oder widerlegt werden können. Spannungen zwischen den auf verschiedene Weise erzeugten Datensätzen und auch unterschiedlichen Theorien können einfach aufgezeigt werden und somit neue, bislang verborgene Eigenschaften von Dunkler Materie gefunden werden. Sämtliche Daten werden der internationalen Forschungsgemeinschaft frei zur Verfügung gestellt.